The Selenium tests tale in the UMP Team
Automated tests are the way to go and while we're at it, it's also a good thing to have some system-wide integration tests, right? Every programmer and tester reading this will surely state now "and the water is wet, Sherlock, can we move on?" OK, so in this article we'll explore a simple question – is it true that the more we automate our system-wide integration tests, the better? In pursuit of the answer, we're going to present an experience report of our UMP Team spending few months of their time to get our large existing Selenium codebase under control. But don't worry, we won't keep you in suspense – our answer is unanimous and emphatic: it's more complicated.
Table of Contents
1. Little bit of theory – how to test it right?
4. Throwing more bodies at the problem
6. So what's the moral of the story?
1. A little bit of theory – how to test it right with Selenium?
Sam Newman, in his holistic book on microservices architecture "Building Microservices", spends significant time describing both the importance and the challenges of using various types of tests. He brings up Brian Marick's model of dividing the tests into 4 quadrants, depending on their business/technology and product support / critique orientations.
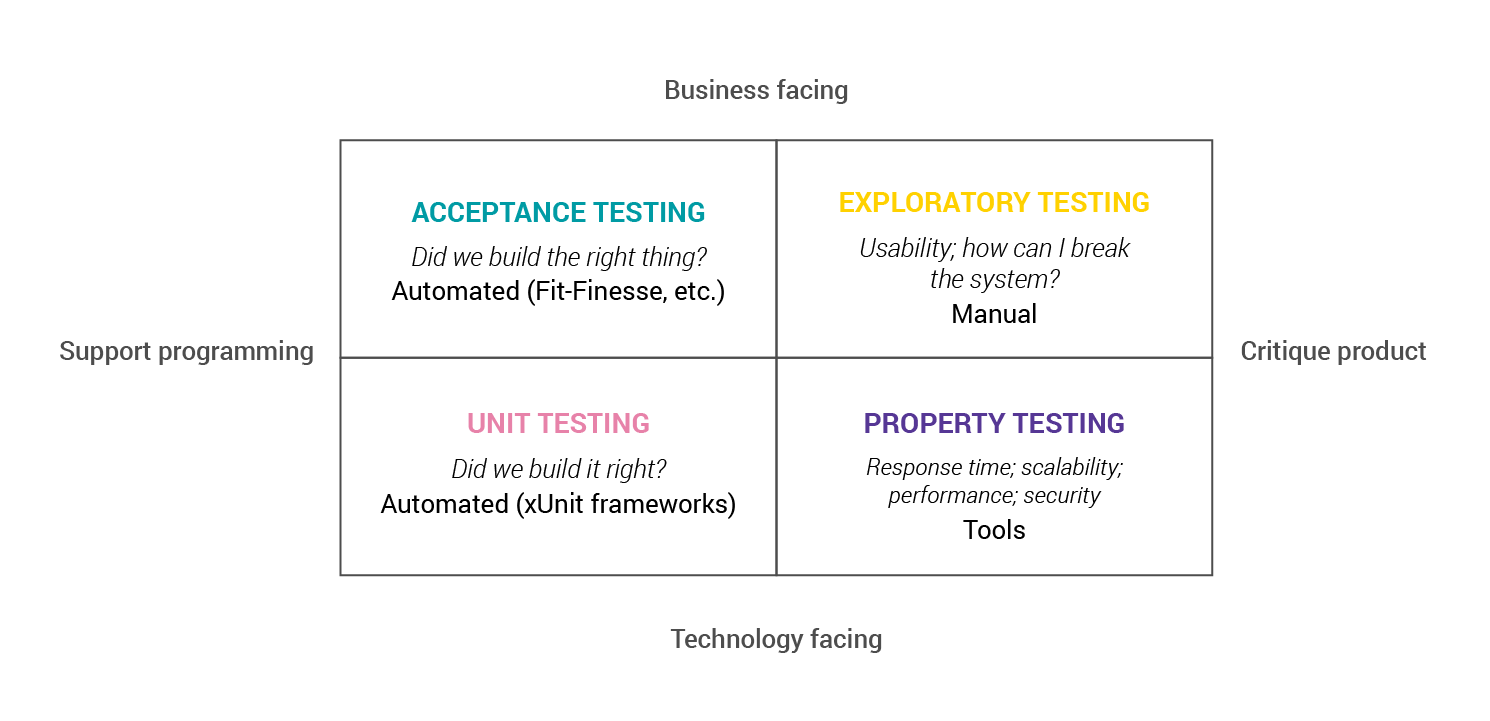
<Figure 1-1. Brian Marick’s testing quadrant. Crispin, Lisa; Gregory, Janet, Agile Testing: A Practical Guide for Testers and Agile Teams, 1st Edition, © 2009. Adapted by permission of Pearson Education, Inc., Upper Saddle River, NJ.>
We can see there’s a choice of various tools to address our different goals. But which are the most important? Should we use all of them equally? Why? To answer these and many other questions Sam Newman introduces additional model by Mike Cohn, called the Test Pyramid:
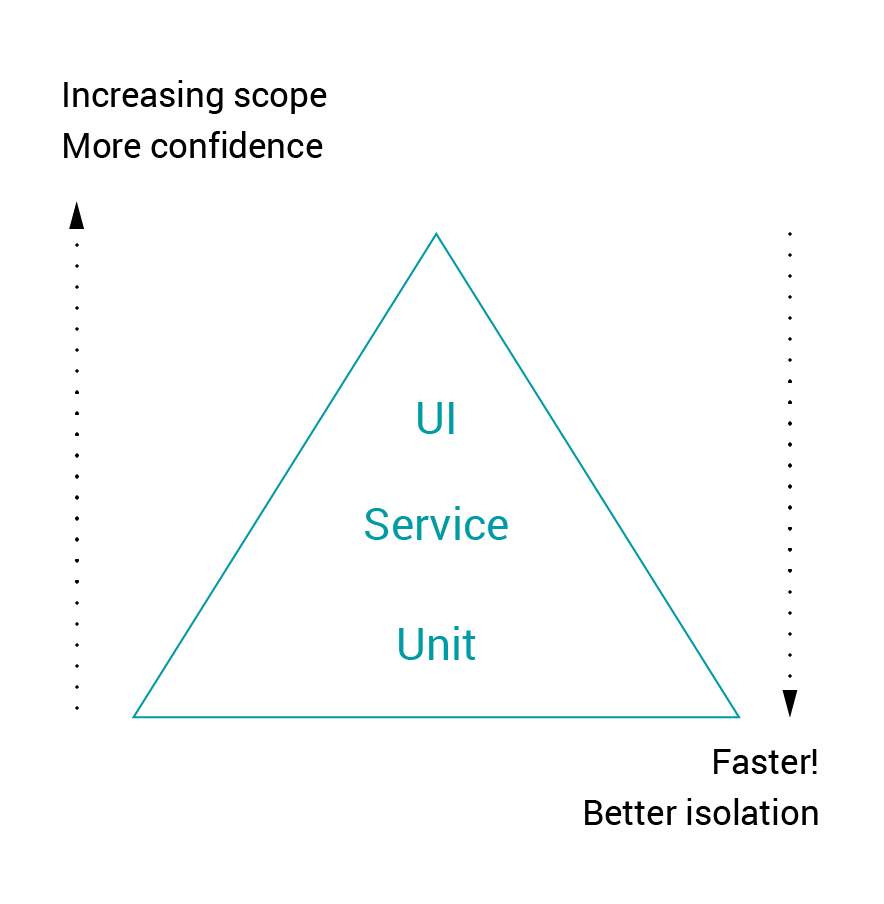
<Figure 1-2. Mike Cohn’s Test Pyramid. Cohn, Mike, Succeeding with Agile: Software Development Using Scrum, 1st Edition, © 2010. Adapted by permission of Pearson Education, Inc., Upper Saddle River, NJ.>
Now we're grouping the tests by our confidence/scope and their feedback time, giving us a simple visualisation of an amount we need. Selenium tests, automating browsers, act on the client side, requiring the whole server-side application, so they naturally fall into the UI tests category. UI tests are at the top of the pyramid for a good reason – they usually take the longest time to run. In his book, Newman describes a case study of the company with the dubious advantage of having so many of them that a single test run lasted more than a day, giving a company a pretty slow and late feedback. Not to mention that without some heavy parallelism and nearly unlimited resources, the term Continuous Integration nearly loses its meaning in such a case. There are a lot of additional questions to cover – what exactly does "Service" mean? Where are performance tests in this model? And finally, what if we have a really complex system UI-wise – do we try to cover it all?
2. Enter AVSystem
The flagship product of our company – Unified Device Management Platform (UMP) allows Telcos to manage their devices on a mass (1M+) scale. This comes with understandable High Availability requirements and this in turn means we've put a lot of effort to have our testing procedures done right. Along with IT industry standards like code review and unit tests we have our QA (Quality Assurance) Engineers in our team to test each new feature manually, write (code-reviewed) Selenium tests and do product-wide regression tests every 2 months before our every new release. They also run tests before product upgrades for our clients and they write Gatling performance tests in clustered environment. They even fix some of the bugs themselves! Sounds too good to be true? Well then, what about those few months of development team fixing the Selenium codebase? Why did it happen and what went wrong? Well, as we're certainly proud of where we are now, our road to get here sure was bumpy.Let's go back a few years
3. Let's go back a few years
Before 2017 we already had 2500+ unit test and there was an initiative to have more broader-scoped tests – Selenium environment was set up and the tests were written, but without much supervision from programmers. Then in the middle of 2017 we finally came to realization that although we had 1300+ Selenium tests... they were super-flaky! In subsequent runs dozens, sometimes above hundred tests would fail and the failures would vary between the test runs. With the benefit of hindsight, we have identified 4 root causes:
- Thread.sleep() commands. GUI takes time to load and this is especially apparent when there are animations with pop-ups, drop-downs, etc. – you often have to work around them and the easiest one is via waiting with Thread.sleep(). And since it's hard to guess the exact amount of milliseconds of sleep, sometimes the fudge factor was a too big order of magnitude, sometimes the tests worked in some runs and crashed in others.
- Tests interdependency – when all the UI tests are launched against one long-running server application, and even one of the test modifies the application state without cleaning up after itself, all subsequent tests with clean-state assumption will crash. Moreover, most Selenium test runners don't guarantee the execution order of tests, so each run had different failures and the culprits weren't easy to identify.
- Selectors – Selenium tests are run from a browser and you have to select elements in DOM. There are two main approaches to do that:
a) XPath selectors – XML elements, i.e. "//tag[text()=’text value‘]" – looks simple and innocent, but often it ended up being much more complex (sixth element of a second-level child of this element) – you can easily see that without coordination with development team these can quickly become outdated and unmaintainable
b) ID / class selectors – allowing for much more precise (and faster) selection of elements, but requiring changing the application code, thus coordinating the work with the development team
As you can guess, the coordination with development team was the issue, so unfortunately the XPaths, often very complicated ones, were the weapon of choice.
As an additional result of missing coordination with development team, tests weren't code-reviewed by developers and inefficient patterns were repeated time and time again – the feedback loop for learning was missing. As a result, the codebase needed restructuring and refactoring.
We were woken up by a huge amount of technical debt we'd allowed to grow over time. We acknowledged the problem and decided to address this in May 2017. We made progress and noticed what needed to be changed. But as the months passed it became apparent what's probably very clear to the readers – combination of above-mentioned 4 factors with the sheer volume of 1300+ tests to go through was not by any means an easy task to solve.

4. Throwing more bodies at the problem
With only a few people working on the case we just couldn’t address the problem properly. Then we made the critical decision to delay some of our features and to take the responsibility for the problem by focusing the attention of our whole team on paying up our technological debt here and now. So we made a list of all the tests needing refactoring, went through them one by one and we refactored our codebase addressing common problems:
- We realized that in most cases Thread.sleep(1000) could be replaced by periodically polling the DOM for certain condition (e.g. every 50ms we've checked for presence of the element we've waited for)
- We extracted the code for above-mentioned DOM polling queries, but also for common operations like login / common setup / cleanup and we wrote down the guidelines to ensure every test had a default application state and that it could be reasoned about independently
- Along with the code refactor and ensuring proper page object model pattern throughout our code-base, we replaced most of XPath selectors with the ones using IDs/classes
- Some things were harder to fix – our tests automatically downloaded the latest version of chrome driver and we've stumbled upon several bugs and instabilities (e.g. entering "root" into text-field ended in "rootoooooo" and the fault was on chrome-driver side). We didn't want to just use a certain chrome driver version and ignore the updates, so in order to reduce the impact on our Selenium test runs we also built text field utilities that entered the text, verified that it's what we attempted to enter and retried a certain number of times if necessary.
So even though the "throwing more bodies at the problem" strategy is often frown upon as a project management Death March, it worked well for us. Were we ashamed that we had not paid attention and allowed the problem to come into existence in the first place? Yes. Was the process costly? Yes, it took the whole team 2 months. Did we have a long-awaited celebration party in Laser Park at the end? You bet we did!

5. Kubernetes to the rescue
Selenium tests are great, they allow us to replace manual scenarios of a whole-product regression testing every 2 months and we're still writing new ones each week. But a reader familiar with Selenium tests might ask a question – how long do they actually run? And that's a really important question to ask, since in 2017 they initially ran around 16 hours!
The Selenium tests in AVSystem are written in Java with JUnit, so back in 2017, using Maven Surefire Plugin and configuring Jenkins workers allowed for parallelism which (after a lot of trial and error) reduced the runtime down to 3-5 hours (the code changes, especially regarding selectors and Thread.sleep() usage, also contributed to this result). The time varied as failed tests took the longest due to timeouts (and the policy to re-run the failures once).
But even those ~3h hours for perfect run weren't really satisfactory for us. So then, in Q4 2018 we embarked on another journey to migrate them to virtualized environment with Kubernetes and Zalenium. Initial efforts were discouraging and test runtime went up to 12 hours due to efforts with correct machine parameters and a large number of test failures – we had to address a whole different class of problems, such as hardcoded addresses of application and mail-servers, timezone issues, etc. Then there was fine-tuning of the number of machines and their resources – after fiddling with a lot of parameters we arrived at Kubernetes test suite using the sweet spot of 20 UMP applications (with separate DBs for each), 20 webdrivers and a powerful JUnit runner machine, totalling 144 cores and 224G of RAM – all on our internal infrastructure! But the impressive record of 1h36min runtime for our 1449 tests was definitely worth it!
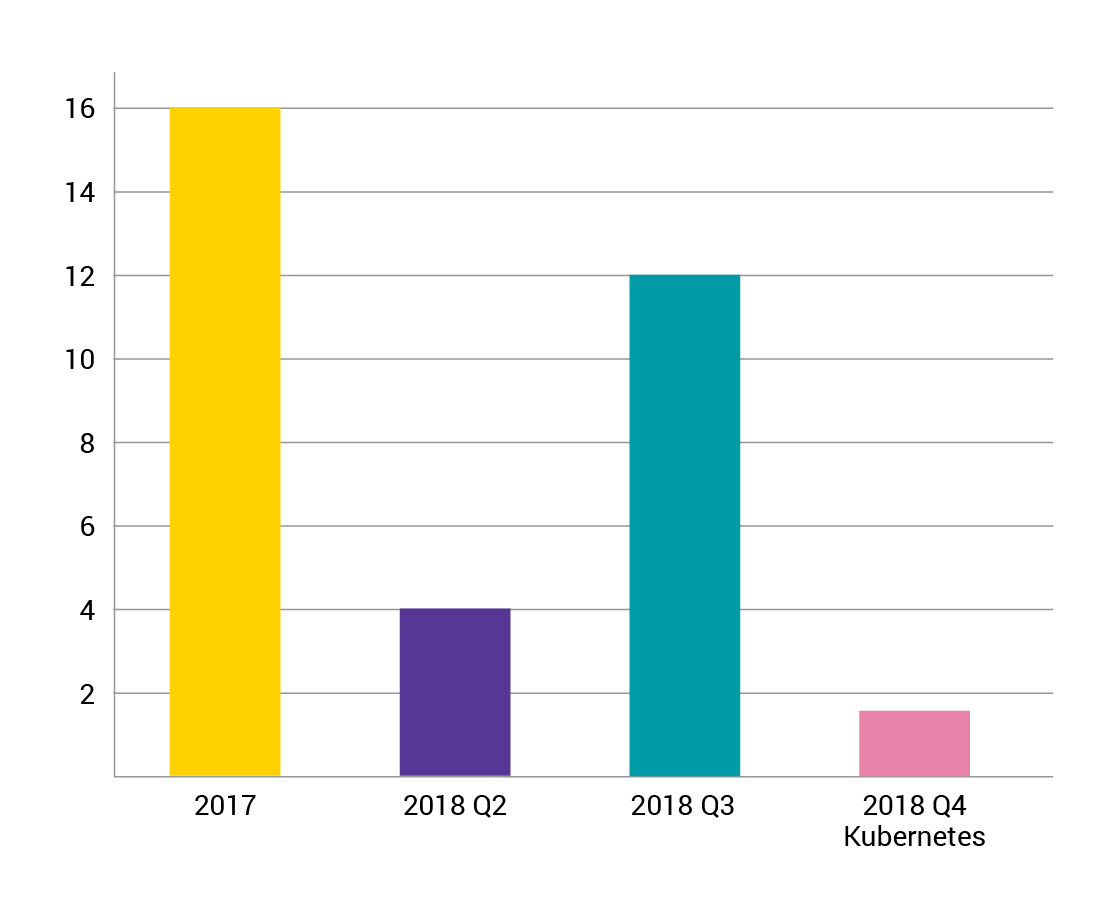
<Figure 1.3 UMP journey with Selenium tests running time>
6. So what's the moral of the story?
Now we're able to answer the question asked at the beginning: “Is it true that the more we automate our system-wide integration tests, the better?– it's definitely turned out to be true for us. We're still enlarging our Selenium test codebase, but it comes with technical challenges that might be hard to get right. Eventually, it's a decision to make – we made it and in the end it worked great for us.
So is everything perfect and is our Selenium effort finally over? Far from it! We still have room for optimization – in tests setup and clean-up we're still using GUI for recurring patterns too much (i.e. once you have a Selenium test for creating your user, you should use REST API for all subsequent tests, it's quicker). Also, the Selenium tests requiring different application configuration (changing which requires application restart) are still something we have to address. On top of that, an hour and a half is still too long to run automatically before merging each pull request. What's more, current Selenium tests sometimes fail and you need to constantly watch over them. It causes interruptions, it takes your time, but it's necessary – otherwise the technical debt will accrue and we learned about the cost the hard way. So the key takeaway #1 is – doing the automated tests right is an ongoing commitment, but the confidence that automated tests can give you is worth it.
In the process we gained a great insight into the problems our QA Engineers had been facing. We understood the importance of QA-DEV coordination and decided to assign a few QA Engineers to sit in the room with the product development team in order for both teams teams to be constantly updating each other and on top of things to do. It became our rule to discuss whether the developer or the QA Engineer would write the Selenium tests for a current feature (depending on their workloads) and the Selenium tests would always be code-reviewed just like the production code. So the key takeaway #2 is – appreciate your QA Engineers and have them as a part of your team for closer cooperation and shorter feedback loop.
Moreover, we started in-house Java courses for our QA Engineers and we made an effort to bring Selenium tests to our other products. We’re still spreading the message of doing Selenium tests right across the company. We gained a greater appreciation for our QA Engineers and their comfort of life grew – some of our QA Engineers from the past became Project Managers, Product Owners and Developers and some became even more awesome at doing Quality Assurance with taking responsibility for our ongoing Selenium effort or learning Scala to implement performance tests in clustered environment with Gatling.
Most of all, we have gained the confidence that if you want to test something right, test it right from the start. If you share our sentiment about strong QA culture, the key takeaway #3 is very simple – check out our offer at the career section.
Recommended posts
- Understanding CPE Requirements for Optimizing Smart Wi-Fi Performance
- Why choose open standards for WiFi service assurance?
- Solving Key Challenges of Fritz!Box Users With Cloud ACS
Subscribe to stay in the loop with all our latest content:
Recommended posts


