
By now, you’ve probably heard the doom-and-gloom stories of the world running out of IPv4 addresses. While they are true – as of 2019, we are officially out of new IPv4 addresses and can only reappropriate the existing ones – there’s no reason to worry because IPv6 is here. If you’re wondering how these two protocol versions differ and if any of them is actually better, you’ve come to the right place – we explain all that and more in our article!
Why we need to move from IPv4 to IPv6
The primary reason for developing the Internet Protocol version 6 was to provide a sufficient number of IP addresses for future use. Despite offering over 4 billion IP addresses, the Internet Protocol version 4 developed in early 1980s, quickly proved not to be enough when confronted with the growing popularity of the internet. The only way to increase the address space was to change its structure. This is why IPv6 address is 128 bits long (compared to 32 bits in IPv4) and uses hexadecimal notation (as opposed to dotted decimal). To learn the exact ins and outs of how both of these addresses are built, you can read our other articles on the Internet Protocol: IPv4 and IPv6.
What IPv6 gives us
There is a price to pay for the increased address space that IPv6 provides us with. The new protocol version was unfortunately not developed to be backward-compatible with IPv4 and so they cannot be used interchangeably. This forces the network owners (such as carriers, service providers, and enterprises) to either switch to the new version entirely or maintain a dual-stack IPv4 and IPv6 approach. Both of these options are expensive, resource-consuming, and don’t really bring any obvious added value to the end customers, which is why providers are hesitant to implement them.
Check out the other articles in this series!
However, the switch is not only inevitable, it does bring certain benefits. This is because IPv6 was not designed just to provide more addresses, but to make the IP communications more efficient. To that end, here are some of the most important changes made to IPv6 vs IPv4.
More address space
This one’s quite obvious, as the primary reason for developing IPv6 was to deal with the issue of an insufficient pool of IPv4 addresses. Thanks to its 128-bit structure, IPv6 provides so many available addresses that every last person on Earth could have a few… trillions of connected devices before we’d run out of IPs again. This means it’s good enough for the foreseeable future, even if that future holds even more IP-address-intensive technologies like the Internet of Things.
Despite all this, precautions still have been made to ensure the efficient use of IPv6 addresses. The problem with IPv4 address availability has been aggravated by “address hoarding” by some companies that were allocated “stockpiles” of addresses that they never actually needed or fully used, but refused to return either. To avoid a similar situation in the future, proper IPv6 address allocation and assignment policies have been put in place.
Easier end-to-end communication
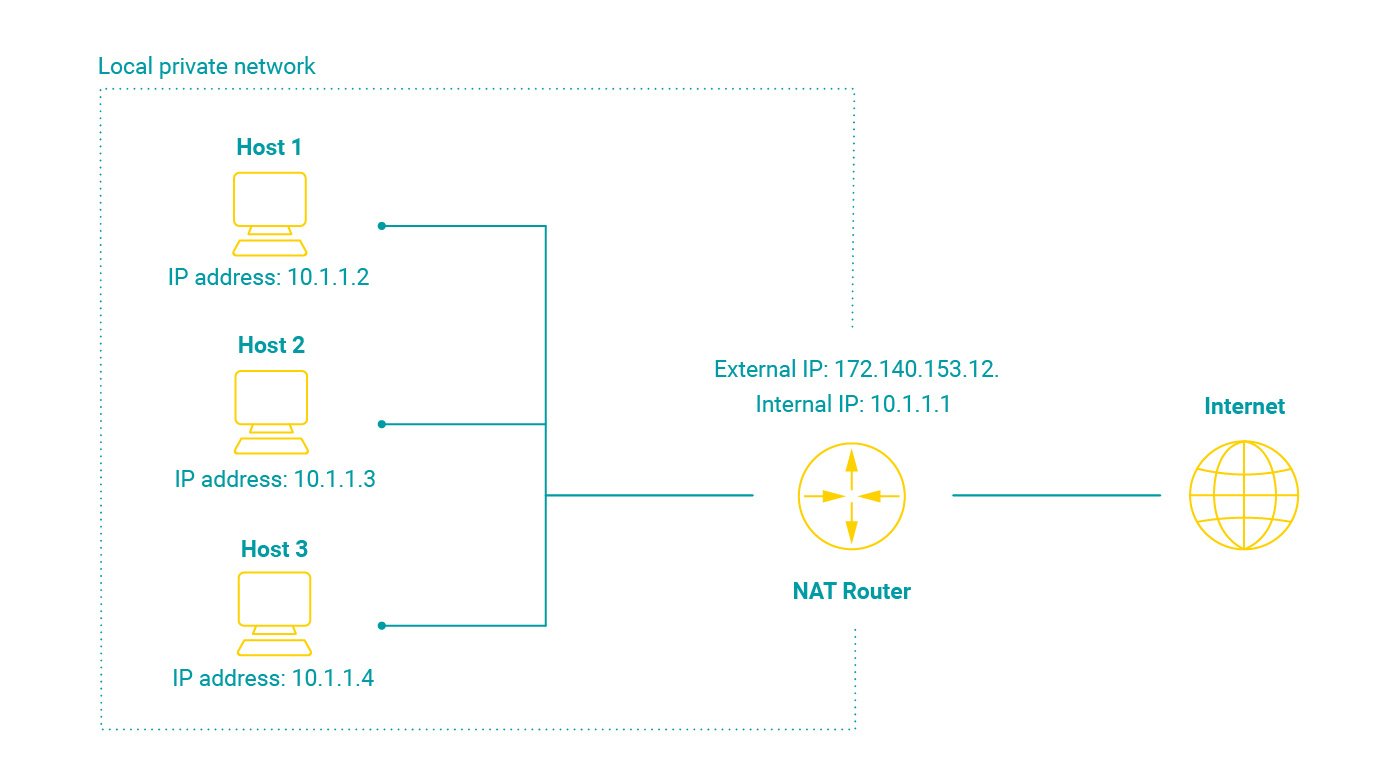
This is a direct result of the increased address space in IPv6 vs IPv4. As all the devices can now have their individual global address, there is no need for complicated routing procedures such as network address translation (NAT).
While NAT is a necessary and popular way of conserving IPv4 addresses, it can also be a significant roadblock to application development when end-to-end communications are concerned, as they often require creative, yet not really efficient workarounds for NAT traversals. Removing that roadblock potentially leads to faster development times, more efficient applications, and conserved resources.
Autoconfiguration
One of the major differences between IPv4 and IPv6 is that the latter allows the so-called stateless address autoconfiguration (SLAAC). With IPv4, you needed a DHCP server to assign an IP address to a device. With IPv6, the device can obtain the network ID (the first 64 bits) from the router and generate its own host ID (the last 64 bits) to create a full IPv6 address. To do that, the device sends a “router solicitation” (RS) asking for the network address, and receives it from the “router advertisement” (RA), which the router also advertises through a periodic unicast.
Does that mean you don’t need a DHCP server anymore? Not really. First of all, if you have a dual-stack IPv4 and IPv6 network, you still need a DHCP server for IPv4 management. But even if you didn’t, you need the server to provide your devices with all the other DHCP options. You might also find that you need to perform a “stateful” configuration (which very much resembles the configuration process in IPv4) if you want more controlled IP address management.
Increased mobility
The limitations of IPv4 have forced the implementation of a special IP protocol for mobile devices called Mobile IP (MIP) which uses triangular routing. Due to the limited pool of IPv4 addresses, it was impossible to allow mobile devices to keep their IP addresses when moving between networks (roaming), which in turn prevented them from being traceable across locations. A workaround to that has been to assign the device a new IP address when it moved to a new network (so-called “visited network”) but route all traffic directed to that device through its network of origin (“home network”) which has been updated with the new address. While a clever solution, you can imagine that it is also very inefficient and creates a lot of unnecessary traffic.
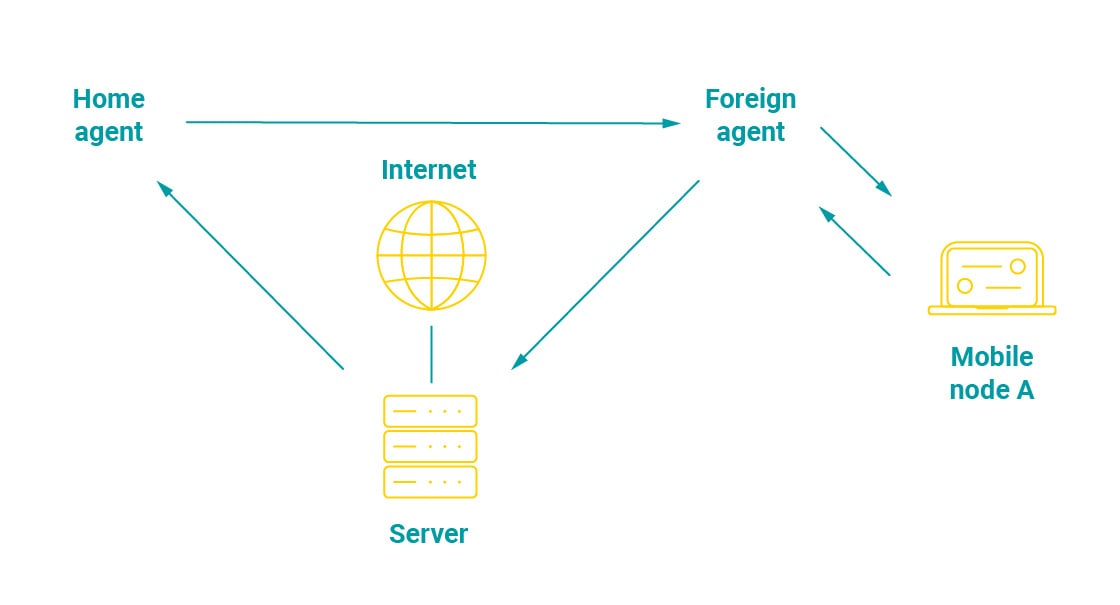
As opposed to mobile IPv4, the process in mobile IPv6 has been optimized so that triangular routing is no longer required and direct routing is used instead. In this scenario, when the device is roaming, the home network is only used to advertise the device’s new IP address, so that it can be contacted directly, and the home network doesn’t have to handle all the traffic.
Multicasting
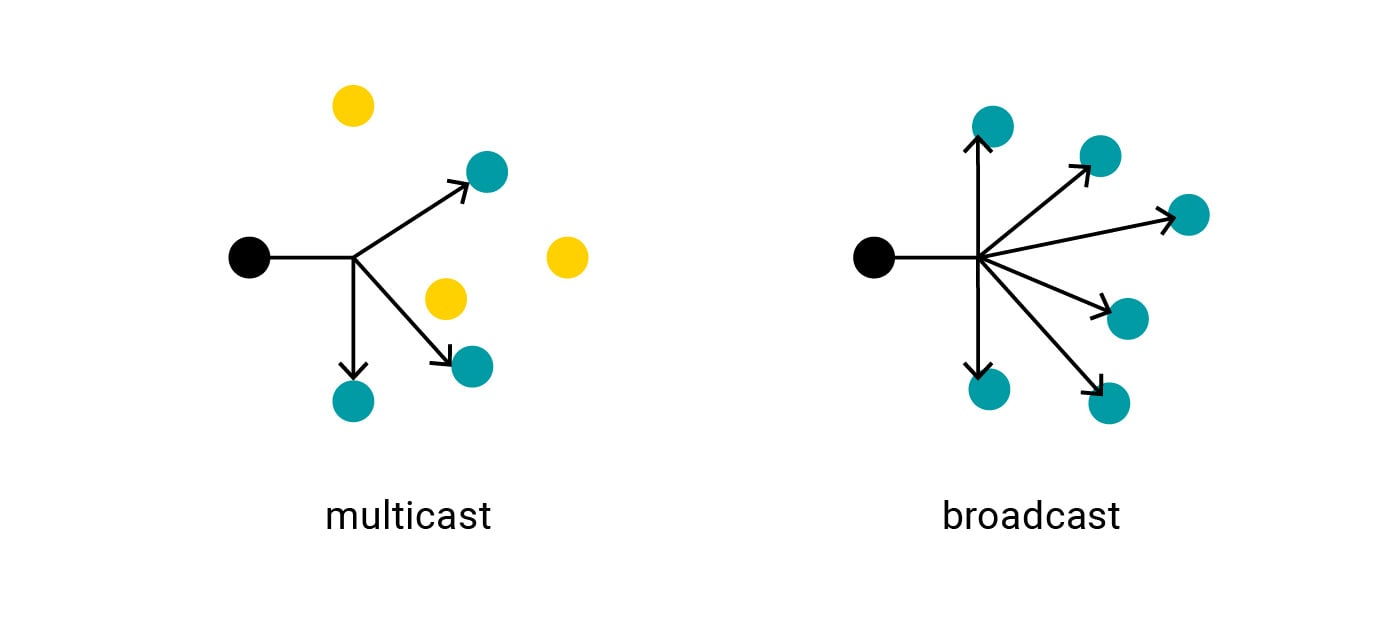
Another important difference between IPv4 and IPv6 is the use of multicasting. This is a method of sending a single message to multiple recipients that have expressed interest in receiving it. While sending a multicast message is possible in IPv4, it is an optional feature, and so broadcasting is used much more commonly. This creates unnecessary overhead, as a broadcast message is sent to everyone in the network indiscriminately, forcing devices to deal with it whether it’s relevant to them or not. This is why, for the sake of efficiency, there are no broadcast messages in IPv6 at all and multicasting is a base specification, not an optional feature.
What happened to IPv5… and the rest?
At this point, you may be wondering why we’re only discussing IPv4 and IPv6, as if there was no other number between them. In fact, this mystery is easier to solve than the absence of Windows 9. At some point, an experimental protocol called the Internet Stream Protocol was developed and assigned a version number 5 in the IP header, even though it was not in any way designed as a successor to IPv4. IPv6, nonetheless, had to take the next available version number to avoid confusion.
And if IPv4 is the first real-life implementation of the protocol, what happened to IPv1 through 3? Before the implementation of IPv4, the Internet Protocol wasn’t used at all – its functions were performed by the Transmission Control Protocol (TCP). The history of theoretical discussions about the previous versions of the protocol and why it was necessary to separate it from the TCP to create TCP/IP suite is a story for another time and can be traced in the Internet Experiment Note (IEN) documents.
So is either protocol version better?
It has to be said that in fact, IPv6 has certain advantages over IPv4. This is only natural, considering that it was developed not only to ensure an appropriate number of IP addresses but also to improve upon the previous version and build on the experience that was gathered in the meantime. While the benefits may not be apparent to end users, they are certainly clear to network administrators and developers dealing with the Internet Protocol. All that’s left now is getting over the hurdle of managing a dual-stack network in the meantime.